
[文献阅读]SiblingAttack-针对面部识别的可迁移对抗攻击的再思考
Information
论文位置:[2303.12512]Sibling-Attack: Rethinking Transferable Adversarial Attacks against Face Recognition
日期:2023-03
出处:CVPR 2023
摘要
由于目标人脸识别(FR)模型的黑盒性质。
提出一种新的FR攻击技术SiblingAttack,首次探索了一种新颖的多任务视角(即,利用多相关任务的额外信息来提高攻击的可迁移性)。
- 直觉上,SiblingAttack选取一组与FR相关的任务,并基于理论和定量分析选取属性识别AR任务作为SiblingAttack中使用的任务。
- SiblingAttack开发了一个融合对抗梯度信息的优化框架,通过:
- 将跨任务特征约束在同一空间下
- 增强任务间梯度兼容性的联合任务元优化(Joint-Task Meta Optimization,JTMO)框架
- 减轻攻击过程中震荡效应的跨任务梯度稳定(Cross-Task Gradient Stabilization,CTGS)方法。
简述
背景
基于深度神经网络DNNs的人脸识别FR模型可能受到对抗攻击。在实际攻击场景中,被攻击FR模型的参数对于攻击者是黑盒的。
一种可行的黑盒策略是通过攻击一个白盒代理模型来构造可迁移对抗样本。
在人脸识别任务上,最近的研究(optimization-based metgods、model-ensmble training、input data transformations)显示了提高攻击可迁移性的有效性。本质上,这些方法通过融合来自集成模型的辅助梯度信息或各种采样/增强策略来防止对抗样本对单个模型/图像的过拟合。然而,他们对online commerical FR的系统是相当悲观的。
相关工作
对于针对FR任务的可迁移对抗攻击:
- Adv-Face使用基于GAN的框架来解决过拟合问题。
- DFANet使用dropout层来提高攻击的可迁移性。
- 使用基于补丁的方法研究针对FR系统的可迁移物理攻击:Adv-Glases和Adv-Hat通过注入补丁帽子或眼睛进行物理对抗攻击
- 生成特定化妆和面部属性的不可感知的扰动
多任务学习
与单任务学习(STl)相比,多任务学习(MTL)是同时学习多个任务,以提高每个任务的准确率。现有的一些工作已经证明了FR和AR人物之间的强相关性。研究表明,FR模型在表示中隐含编码潜在的属性特征,FR模型的隐含层可用于进行属性预测。AR任务的模型可以学习到更鲁棒的特征,因此可以它用来提高FR的鲁棒性。
多任务训练可以学习到更多的对抗鲁棒特征。
实现
本论文认为,现有的方法仅从单个任务中手记的对抗梯度,从而忽略了进一步提高可迁移性的潜在可能性。
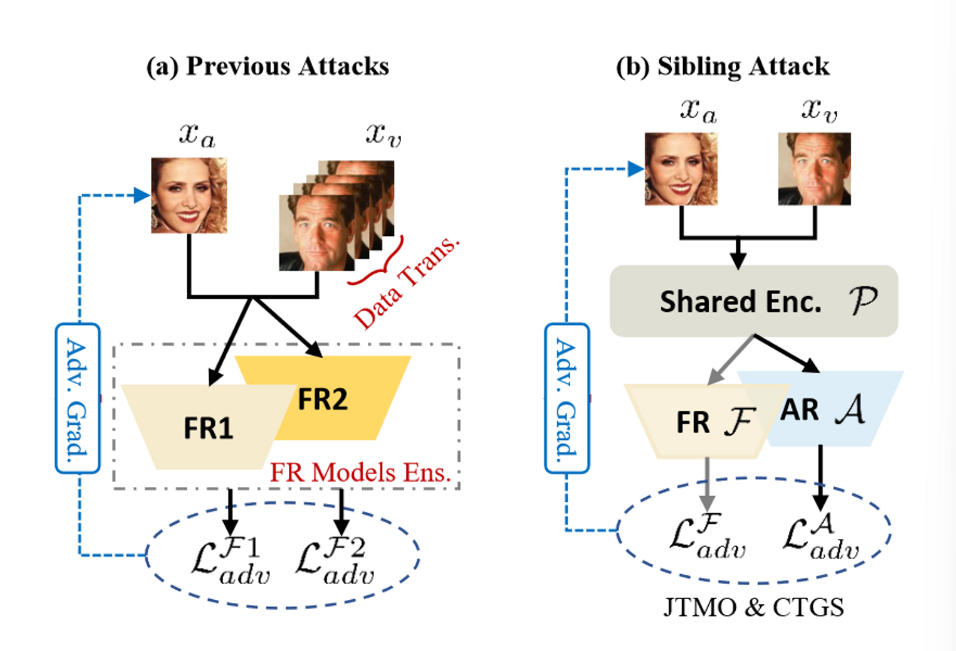
多任务学习(MTL)方法指出,在相关任务之间进行多任务或来拟合任务训练,可以学习到更加鲁棒和通用的特征,从而提高整体的泛化能力。本论文寻求在跨任务范围内提高FR任务的攻击可迁移性。为了探究多任务环境下FR攻击的可迁移性,存在两个挑战:
- 在执行多任务攻击时,如何确定一个合适的辅助任务作为FR任务的合适候选
- 如何充分利用两个任务的对抗信息,从而提高可迁移性
基于这两个问题,我们假设一个与面部相关的任务,可以为目标FR任务提供相关但多样的对抗梯度信息来补充内在缺失的对抗知识,可以被认为是一个很好的辅助任务候选者,命名为sibling-task(同胞任务?)。
AR模型能够学习到文件的身份特征,可以用来增强FR的识别稳健性。反过来,FR特征也隐式地编码了潜在的面部属性特征。此外,我们进行了定量的结果来展示AR任务的有效性。为此,我们利用一个相关的AR任务作为sibling-task来提高攻击的可迁移性,即SiblingAttack。
由于不同任务的特征空间和梯度空间存在较大差异,如果不考虑更好的梯度融合和稳定的训练策略,直接优化FR或如AR模型将导致攻击可迁移性十分有限。在SiblingAttack中,我们首先采用应参数共享架构作为我们的骨干攻击框架,将他们限制在相同的特征空间内,如图1(b)所示。
接下来,我们基于元学习的高层理念设计了一种交替联合任务元优化(JTMO)算法,以进一步提高两个任务之间的梯度兼容性。最后,为了缓解训练震荡效应,我们提出了一种用于稳定对抗样本优化的跨任务梯度稳定(CTGS)策略。
实验
大量实验表明,SiblingAttack比目前最先进的FR攻击技术有非常明显的优势,在最先进的预训练FR模型和两个著名的、广泛使用的商业FR系统Face++人脸识别和Microsoft face API上,攻击成功率平均提高了12.61%和55.77%,值得注意的是,SiblingAttack在两个常用数据集上攻击广泛使用后的Face++商业人脸API的ASR分别达到了86.50%和96.10%,而目前的研究结果进分别达到了58.10%和64.30%。
贡献
- 提出利用相关AR任务中的对抗信息来生成对抗人脸识别的高度可迁移的对抗样本
- 提出SiblingAttack方法,以有效的方式联合学习来自多个任务的对抗信息
方法
概述
针对FR的靶向对抗攻击,即impersonation-attack模拟攻击,通过欺骗目标FR模型,使攻击者误认为与目标具有相同的身份。本论文主要针对Adv-makeup( Advmakeup: A new imperceptible and transferable attack on face recognition. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence (IJCAI), pages 1252–1258. International Joint Conferences on Artificial Intelligence Organization, 8 2021. Main Track)和针对深度人脸识别的可迁移对抗攻击(Towards transferable adversarial attack against deep face recognition. IEEE Transactions on Information Forensics and Security (TIFS), 16:1452–1466, 2020.)进行研究。伪造攻击的目标可以表述为:
$\min \limits_{\epsilon_a} \mathcal{L}(x_a + \epsilon_a, x_v), s.t. ‖\epsilon_a‖_p ≤ ξ$,(1)
其中:
- $x_a∈\mathcal{R}^{H·W·C}$为攻击面孔
- $x_v∈\mathcal{R}^{H·W·C}$为目标被攻击面孔
- 对攻击者的扰动$a∈[0,1]^{H·W·C}$受到$\ell_p-norm$($p∈{0,2,∞}$)的约束。在这项工作中,$p=∞$.
- $ξ$ 是一个小的常数用来约束$\epsilon_a$
- $\mathcal{L}(·)$表示对抗损失函数
SiblingAttack框架
如图1(b)所示,为了避免较大的特征方差,我们在SiblingAttack中采用了一种优秀的应参数共享架构作为主干。图1(b)所示的白盒代理模型记为$\mathcal{S(P;F;A)}$,其第一个部件是一个共享参数编码器$\mathcal{P}$,然后代理模型分支成两个子网络:一个FR分支$\mathcal{F}$和一个AR分支$\mathcal{A}$。给定攻击图像$xa$和目标图像$x_v$,我们的目标是通过$\mathcal S$生成对抗样本$x{adv}$来欺骗黑盒目标FR模型$\mathcal T$。
具体来说,对每个$x_a$和$x_v$,$\mathcal S$的每个分支分别通过$\mathcal F$和$\mathcal A$计算其对应的输出高层特征向量${f_a^{\mathcal F},f_v^{\mathcal F}}$和${f_a^{\mathcal A},f_v^{\mathcal A}}$。然后,这些特征被用于计算针对FR的目标攻击的相应对抗损失。如下所示:
$\mathcal L_{adv}^=1-cos(f_a^,f_v^*)$,(2)
其中:
$*∈{\mathcal{F,A}}$,我们使用两个特征向量之间的余弦值作为评价指标来衡量他们的相似性。
基于此,本文对联合仿冒攻击的主要目标函数进行了如下设计:
$\min\limits{\epsilon_a}λ_1 ·\mathcal{ L^F{adv} + λ2 · L^A{adv},\ s.t. ||\epsilon_a||_p ≤ ξ}$,(3)
其中:
$λ_1$和$λ_2$为需要进行取舍的超参数。
联合任务元优化(JTMO)
对于元学习框架,交替采用梯度可以提高进行特征学习的跨数据集兼容性,交替采用梯度可以提高进行特征学习的跨数据集兼容性,从而增强可推广性。为此我们可以通过在两个任务之间获得更好的梯度兼容性来构建可迁移的对抗样本。
因此,本论文提出了一种新的针对对抗场景的优化策略,即联合任务元优化(JTMO)。如图2所示,在JTMO中,我们模仿元学习的参数更新策略,而不是直接计算两个任务的加权平均对抗损失。
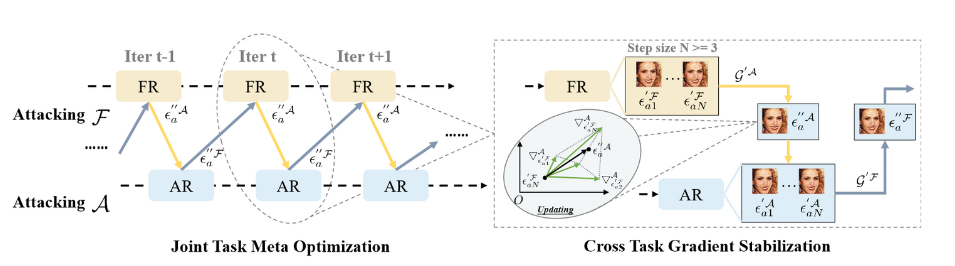
为了生成对抗样本,我们必须添加一个扰动$a$来迭代地修改$xa$中的像素。对于每次迭代,我们从$\mathcal S$中交替选择一个分支,然后进行前向和后向传播,从相应的对抗损失$\mathcal{L{adv}^{F}}$或$\mathcal {L_{adv}^{A}}$中计算梯度。分支选择的先后顺序不会影响最终的性能。对于每次迭代中的每个分支,更新后的扰动$\epsilon_a’$可以通过计算得到:
$\epsilon^′a ← \prod {\epsilon_a − α · sign(γ_1 · \triangledown{\epsilona} L^∗ {adv}(x_a + \epsilon_a, x_v))}$,(4)
其中:
- $\prod{·}$表示由$\ell_∞$约束保证的投影函数
- $\alpha$表示学习率
- $\gamma_1$为更新超参数
- $*∈{\mathcal{F,A}}$
然后,我们利用更新后的扰动$\epsilon^′a$计算$L^{^′}_{adv}$。
最后,我们聚合所有梯度信息来更新扰动,具体为:
$\epsilon^{′′}a ← \prod {\epsilon^′_a − α · sign(γ_1 · \triangledown{\epsilona^′} L^{*^′}{adv}(x_a^′ + \epsilon_a^′, x_v))}$,(5)
其中:
- $x^′_a=x_a+\epsilon_a$,$\gamma_2$为更新的超参数
- $\epsilon^{′′}_a$是每次迭代的对抗扰动输出
受元学习的启发,我们的优化策略首先从扰动参数的两个分支交替收集梯度,然后再每次迭代中使用梯度在两个任务之间交替优化$\epsilon^{′′}_a$,以获得优化兼容性。
跨任务梯度稳定(CTGS)
在两个人物之间更新对抗扰动,不可避免地会引起震荡的副作用,并导致次优解。这种副作用可以归因于两种不同的任务具有不同的梯度更新方向。
基于单任务对抗攻击方法中,历史梯度和适当梯度聚合可以稳定优化过程从而提高攻击的可迁移性的特性,本论文设计了一种新的更新策略,即交叉任务梯度稳定(CTGS),以进一步提高SiblingAttack的攻击可迁移性。
如图2所示,在优化过程的每一次迭代中,为选定的任务分支定义一个更新步长$N$,例如$\mathcal F$。则$N$个对抗扰动$\mathcal {E^{′F}}={\epsilon^{′\mathcal F}{a1},…,\epsilon^{′\mathcal F}{aN}}$可以通过连续计算公式(4)来迭代处理。接下来,我们将扰动添加到攻击图像$xa$中,生成对抗样本,并将其发送到另一个任务分支$\mathcal A$中,计算其对应的梯度图$\mathcal G^{′A}={\triangledown^\mathcal A{\epsilon^{′\mathcal F}{a1}},…,\triangledown^\mathcal A{\epsilon^{′\mathcal F}_{a_N}}}$。因此,当更新$\mathcal A$上的$\epsilon^′_a$时,我们可以在式(5)上得到方程:
$\epsilon^{′′\mathcal A}a ← \prod {\epsilon^{′\mathcal F}{aN} − α sign[γ_2 ( \triangledown{\epsilon{aN}^{′\mathcal F}}^{\mathcal A}+\gamma3\sum\limits{i=1}^{N-1}\triangledown{\epsilon{ai}^{′\mathcal F}}^{\mathcal A})]}$,(6)
按照这个更新过程,来自$\mathcal F$的历史对抗梯度在$\mathcal A$上的计算梯度被聚合以稳定当前的优化。$\gamma_3$是一个用以平衡训练权重的超参数。由于历史对抗梯度只提供辅助梯度信息,而不主导主更新方向,因此我们选择$\gamma_3$作为较小的数值。
该策略通过利用来自另一个任务分支的历史$N-1$个对抗样本的跨任务梯度,增强了优化的稳定性,提升了可迁移性。
SiblingAttack的整体流程如算法1所示:

实验
数据集
- Celeb A-HQ
- LFW
评价指标
采用Attack Success Rate(ASR)评估。计算公式:
$\mathsf{ASR}=\frac{\text{No. of Comparisons ≥}\mathcal T}{\text{Total No. of Comparisons}}$,(7)
分子定义对抗攻击是否成功,其接受来自黑盒模型的对抗样本和两性样本在相应的阈值$\mathcal T$上的相似性分数。
目标模型
- 离线模型:
- IR152
- IRSE50
- FaceNet
- IR550
- ResNet101
- 在线模型
- Face++
- Microsoft
对于离线FR模型,本论文使用IR152、IRE50和FaceNet作为白盒,生成对抗样本,并在其他模型上评估攻击的可迁移性。离线模型的所有阈值均从LFW数据集中的图像获得。
对于AR模型,本论文使用IR152和Mobileface作为骨干网络,并在MSCeleb-1M和CelebA-HQ上进行训练,以保证在AR任务上的性能。
参数设置
在SIblingAttack中,对于FR任务和AR任务,白盒代理模型的结构均为IR152.根据先前工作的实验配置,设置:
$ξ=40/255$
$\ell_∞$
$\alpha=2/255$
$T=200$
$N=4$
$(\gamma_1,\gamma_2,\gamma_3)=(0.1,0.9,0.01)$
实验结果
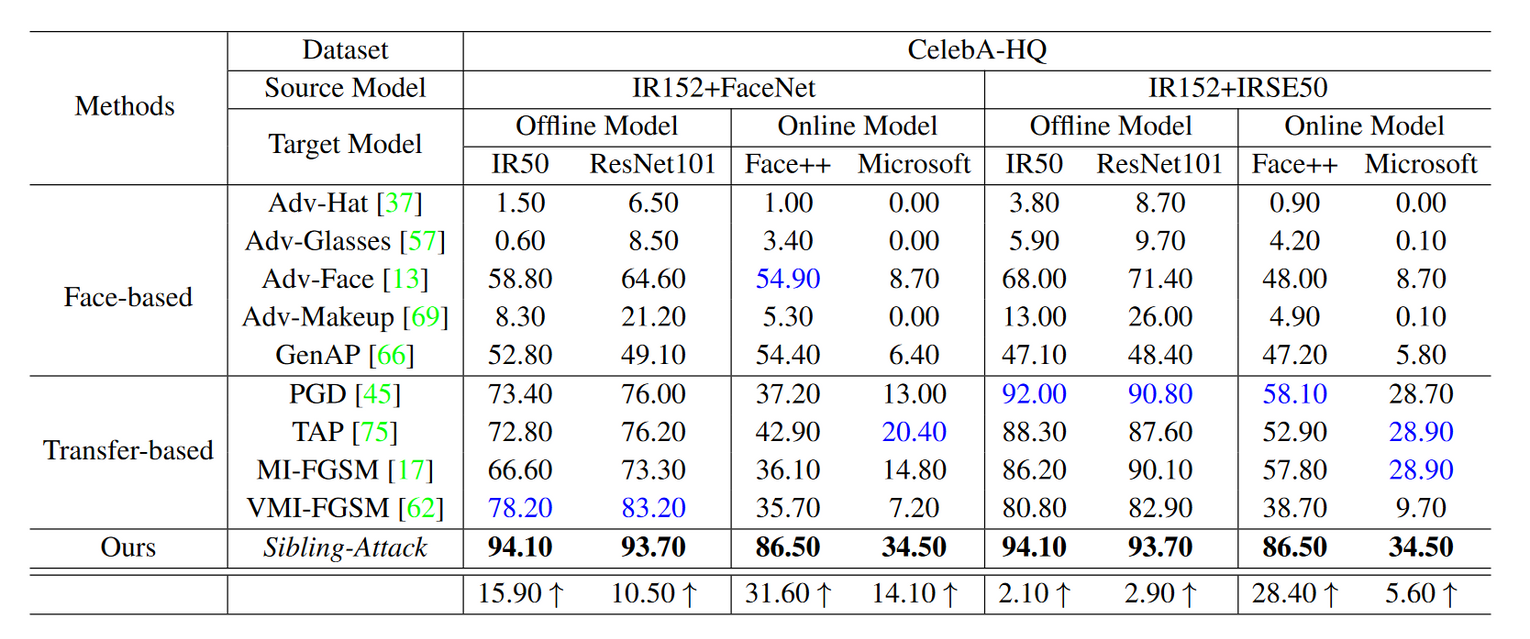
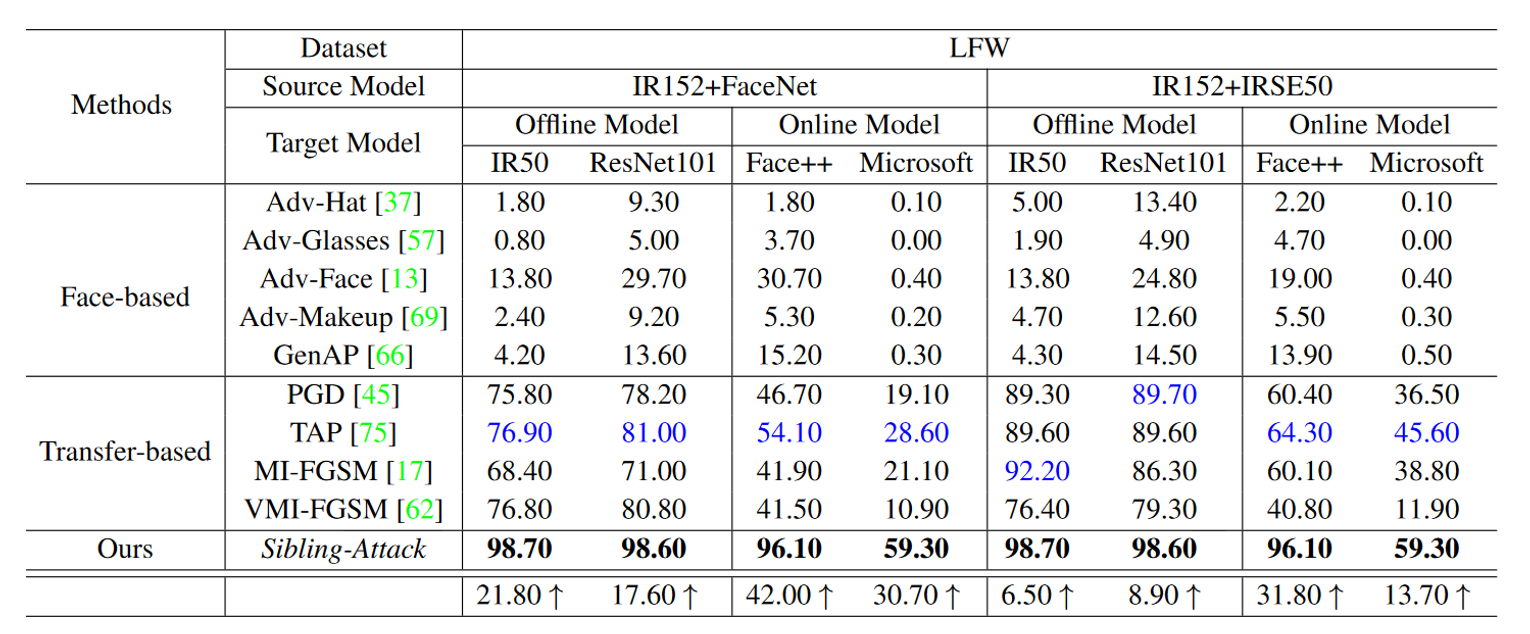
由表2表3可知,基于补丁的方法在大多数目标模型上具有较弱的可迁移性,因为其是针对攻击区域较小的物理攻击而设计和调整的。结果表明,与所有其他基于人脸的方法相比,攻击整个人脸的对抗样本即Adv-Face具有最好的可迁移性。
然而,从表2中Celeb-AHQ结果可以看出SiblingAttack仍能显著超过Adv-Face。
消融实验
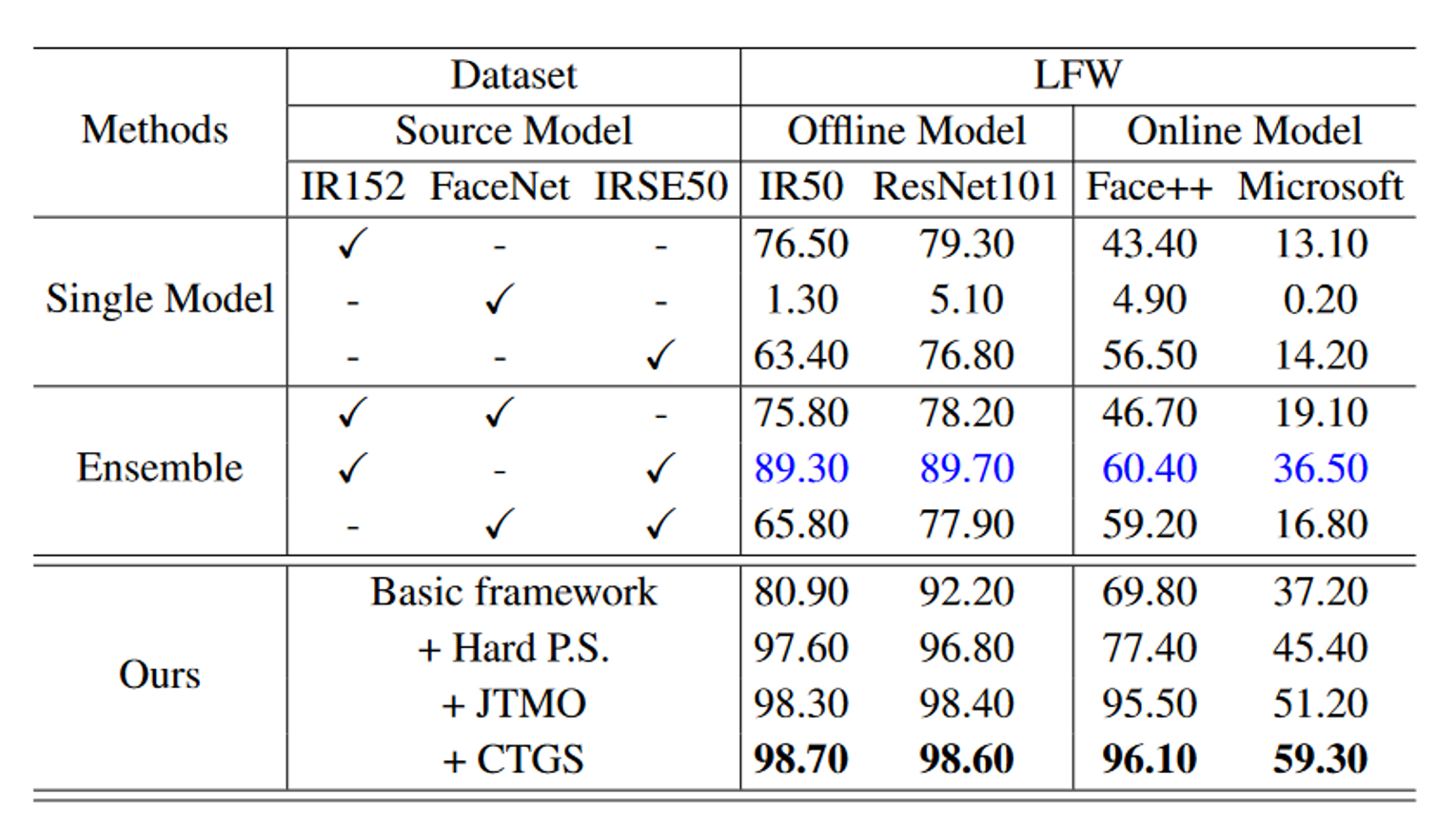
具体来说,SiblingAttack包含以下部分:
- 硬参数共享(Hard P.S.)
- 联合任务元优化(JTMO)
- 跨任务梯度稳定(CTGS)
在实验中,可以很好证明使用AR任务中的信息可以帮助提高针对FR任务的攻击可迁移性。此外,ASR随着每个拟议组件的添加而逐渐增加,并且显著优于其他基于单一集成训练的模型。
可视化分析
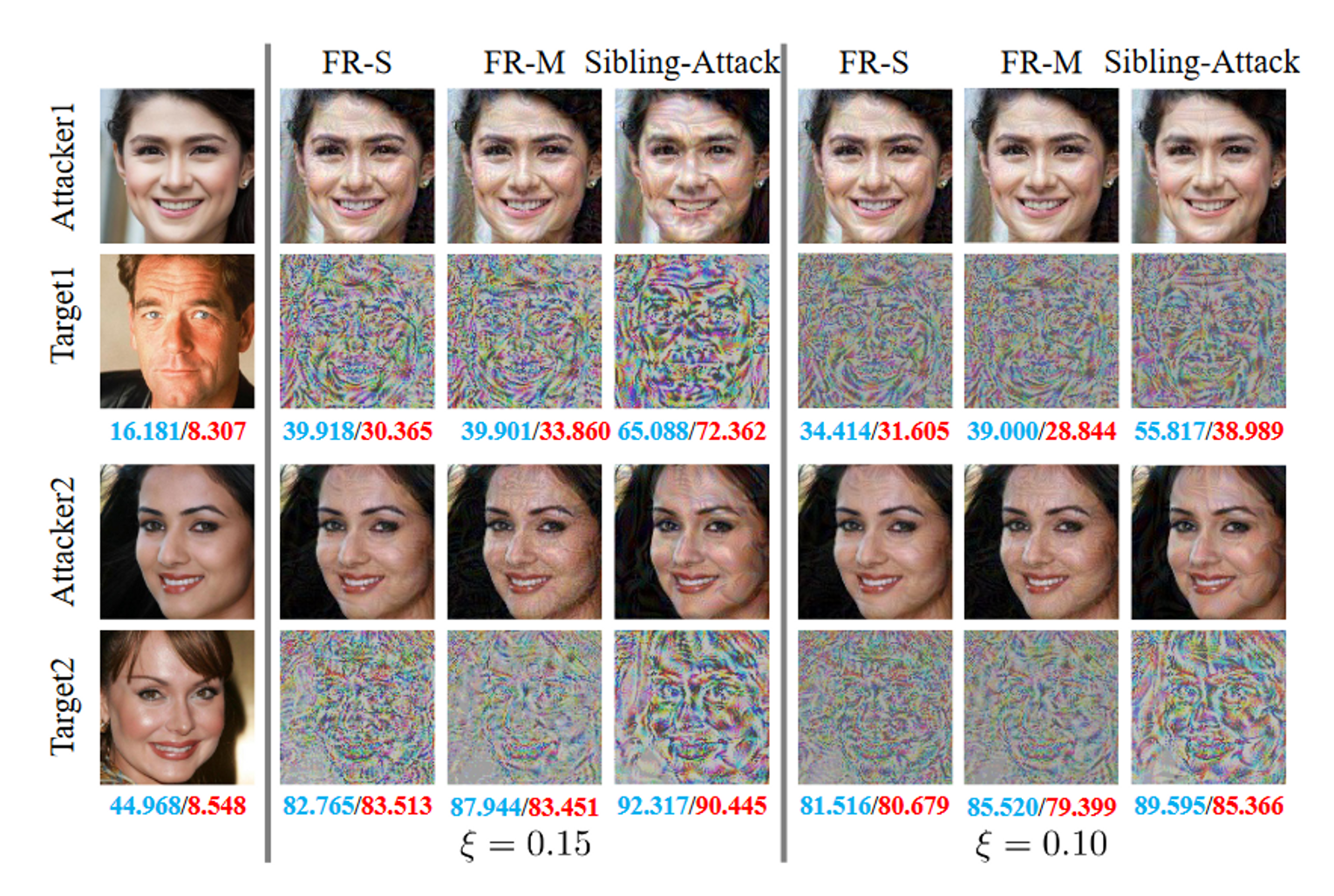
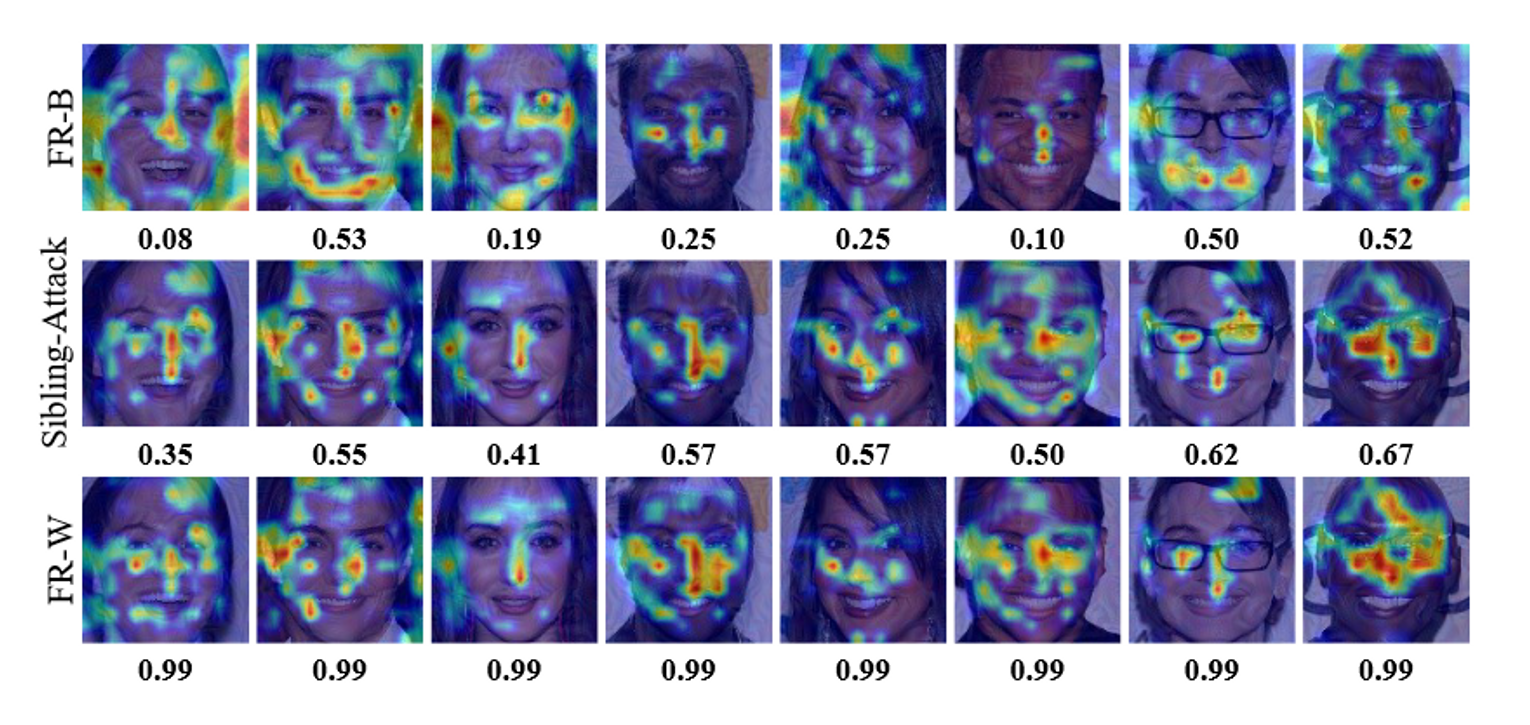
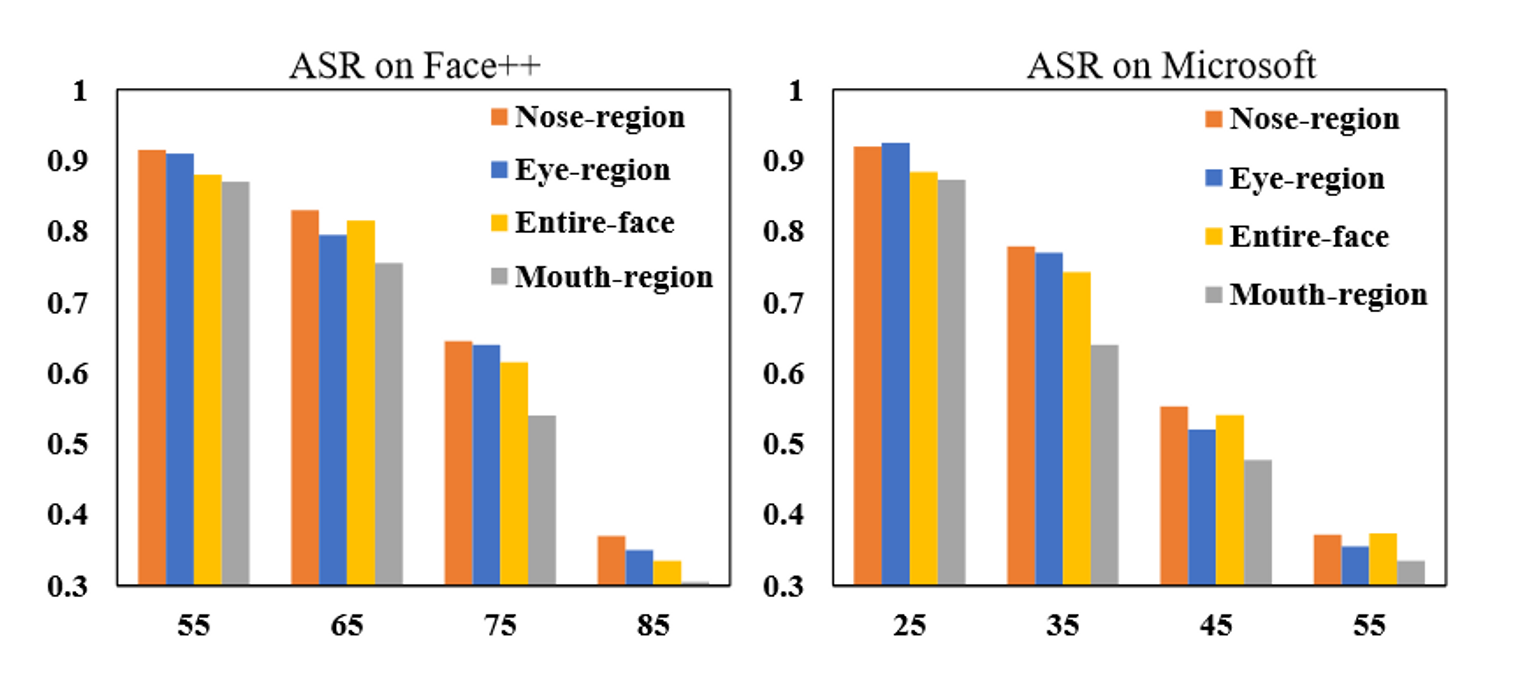






![[日常] v我50来点文子哥的保研经历](https://image-host-mooliht.oss-cn-beijing.aliyuncs.com/img/1728380966977.png)
![[计算机网络]可靠传输协议迭代设计-来跟👴握个手](https://image-host-mooliht.oss-cn-beijing.aliyuncs.com/img/v2-479a601f5f20bca19018dddb68c0d708_720w.jpg)